
《深度探索C++对象模型》
C++对象模型
和重要的一点就是用C++时,必须把Python的"一切皆对象"的思维转变过来,在python里确实包括连函数都是对象,在调用函数时都会创建一个method对象然后用完销毁(应该是根据Type找到类函数地址创建对应的函数实例,你也可以给这个标识符赋上其他的函数对象使其记录成其他函数的引用),对象的dict也可以不断扩充新的成员……
但是在C++中,由于我们是有编译的,直接生成确定的机器代码、地址、数值,而不是跑在虚拟机运行时上的,所以真的就只有类实例是对象,其他都不是,都是编译时就确定的信息,因而:
- 函数地址都是编译时就确定的,即使是虚函数,你类代码确定了,函数地址自然也是确定的,只是对具体的类对象来说可能绑定的函数不一样而已
- 许多成员像static,const,他们的地址也是确定不变的
在C++中以类的形式实现对象之后,会增加多少布局成本?(字节对齐) (虚函机制) (继承机制)
一般来说,不会增加任何成本。
C++的成本来源就是 vitrual 机制,无 virtual 就无额外的开销,这是非常好的设计
在C++中,成员变量分为普通和static,而成员函数分为普通、static和virtual,其中 只有普通成员变量占用对象的内存
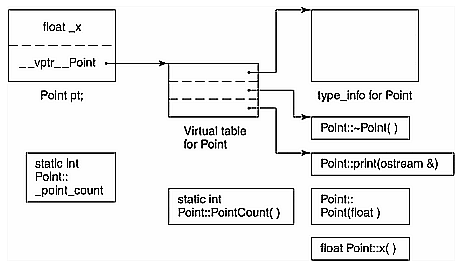 RTTI: 一般来说,每一个 class 相关联的 type_info 对象的指针 通常也保存在 vtable 的第一个 slot 中。
RTTI: 一般来说,每一个 class 相关联的 type_info 对象的指针 通常也保存在 vtable 的第一个 slot 中。Virtual Function机制 需要以下2个步骤来支持:
- 每一个class产生出一系列 指向virtual function的指针,放在一个被称为virtual table的表格中;
- 每一个class object被添加了一个指针vptr,指向相对应的vtable。vptr的设置由编译器全权负责,程序员无需关心。
> 对于虚函数,是通过vptr找到vtable,再由vtable中的指针指向实际的虚函数地址的;而对于其他函数,它call function其实编译期就可以确定函数地址了(通过class),就没有指针这么动态
> 一个vtable对应一个class,一个vptr才对应一个class object(python用多了老搞混)
引入继承后的对象模型成本:
- 如果是普通的继承,父对象被直接包含在子对象里面,这样对父对象的存取也是直接进行的,没有额外的成本;
- 如果是虚拟继承,则父对象会由一个指针被指出来,这样的话对父对象的存取就添加了一层间接性,必须经由一个指针来访问,添加了一次间接的额外成本。
C++优先判断一个语句为声明:当语言无法区分一个语句是声明还是表达式时,就需用用一个超越语言范围的规则 —— 优先判断为声明。
struct和class关键字的意义:
◦ 它们之间在语言层面并无本质的区别,更多的是概念和编程思想上的区别。
◦ struct用来表现那些只有数据的集合体POD(Plain OI' Data)、而class则希望表达的是 ADT(abstract data type)的思想;
◦ 由于这2个关键字在本质是无区别,所以class并没有必须要引入,但是引入它的确非常令人满意,因为这个语言所引入的不止是这个关键字,还有它所支持的封装和继承的哲学;
◦ 可以这样想象:struct只剩下方便C程序员迁徙到C++的用途了。
C++只保证处于同一个access section的数据,一定会以声明的次序出现在内存布局当中。C++标准只提供了这一点点的保证。
• 与C兼容的内存布局: 组合,而非继承,才是把 C 和 C++ 结合在一起的 唯一可行 的方法。
只有使用组合时,才能够保证与C拥有相同的内存布局,使用继承时的内存布局是不受C++ Standard所保证的(很多编译器也可行,但是标准未定义)
普通类

成员变量依据声明的顺序进行排列(类内偏移为0开始)
static成员变量和函数都存放在类的对象之外,不过sizeof对象内存时依然占用(比如+static int就+4字节)
继承类

子类会需要先排布父类变量,然后再排布自己的变量,这点符合预期
父类+虚函数(virtual)

编译器是把虚表指针vfptr放在了内存的开始处(0地址偏移),然后再是成员变量;
下面生成了虚表vftable,紧跟在&Base1_meta后面的0表示,这张虚表对应的虚指针在内存中的分布,下面列出了虚函数
编译器是在构造函数创建这个虚表指针以及虚表的。
虚函数表到底在哪个地方?
虚函数表是一个数组,存储虚函数的地址,虚函数的个数在编译时期可以确定
VS测试vftable存放在字符串常量区。由vptr指向
如何获取虚表指针?int* p = (int*) this; int f = *p; void* pf =(void*)f;
编译器是如何利用虚表指针与虚表来实现多态的呢?
当创建一个含有虚函数的父类对象时,编译器在对象构造时将虚表指针指向父类的虚函数;
同样,当创建子类的对象时,编译器在构造函数里将虚表指针(子类只有一个虚表指针,它来自父类)指向子类的虚表(这个虚表里面的虚函数入口地址是子类的)。
所以,如果是调用Base *p = new Derived(); 生成的是子类的对象, 这时候p->VirtualFunction,实际上是p->vfptr->VirtualFunction 调用的是子类的虚函数,这就是多态了。
子类+虚函数

虚表指针只会有一个,因为重写了父类的虚函数,所以指向的是子类的虚函数
如果没有重写父类的虚函数,指针会指向父类的
重写或自己新添加的虚函数,指针会指向子类的
多重继承

它并列地排布着继承而来的两个父类DerivedClass1与DerivedClass2,还有自身的成员变量e
这种情况下 会有两个虚函数表指针,指向两个虚函数表
如果Child中定义了虚函数,则child中覆盖的虚函数会替换掉两个表中同名的虚函数指针位置。若是普通多重继承,根据继承顺序,child中新定义的虚函数的地址会附加到第一个虚表指针指向的虚函数表的后面。
这里不会有3个虚表指针,子类只会去使用父类的虚表指针,而由于是多继承因此有多个父类虚表,也有的编译器会把虚表合并成一个。
虚继承底层实现原理与编译器相关,一般通过虚基类指针和虚基类表实现,每个虚继承的子类都有一个虚基类表指针(占用一个指针的存储空间,4字节)和虚基类表(不占用类对象的存储空间)(需要强调的是,虚基类依旧会在子类里面存在拷贝,只是仅仅最多存在一份而已,并不是不在子类里面了);当虚继承的子类被当做父类继承时,虚基类指针也会被继承。
实际上,vbptr指的是虚基类表指针(virtual base table pointer),该指针指向了一个虚基类表(virtual base table),vbt虚表中记录了虚基类与本类的偏移地址;通过偏移地址,这样就找到了虚基类成员,而虚继承也不用像普通多继承那样维持着公共基类(虚基类)的两份同样的拷贝,节省了存储空间。
在这里我们可以对比虚函数的实现原理:他们有相似之处,都利用了虚指针(均占用类的存储空间)和虚表(均不占用类的存储空间)。不同之处,虚基类依旧存在继承类中,占用存储空间;虚函数不占用存储空间。
虚基类表存储的是虚基类相对直接继承类的偏移;而虚函数表存储的是虚函数地址。
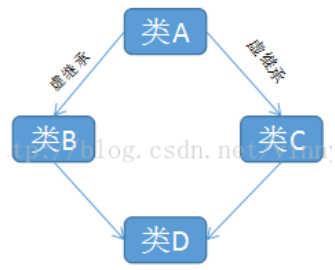 内存布局示例:
内存布局示例: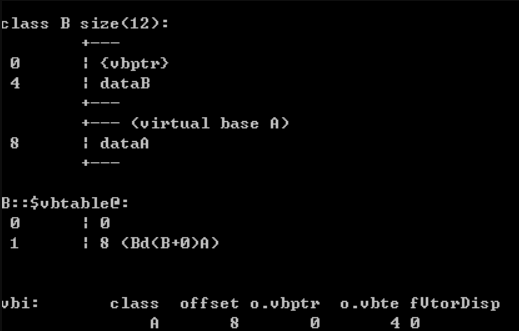 B:vbptr + offset of virtual base A
B:vbptr + offset of virtual base A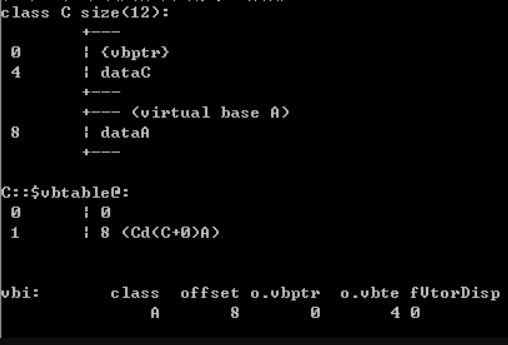 C:vbptr + offset of virtual base A
C:vbptr + offset of virtual base A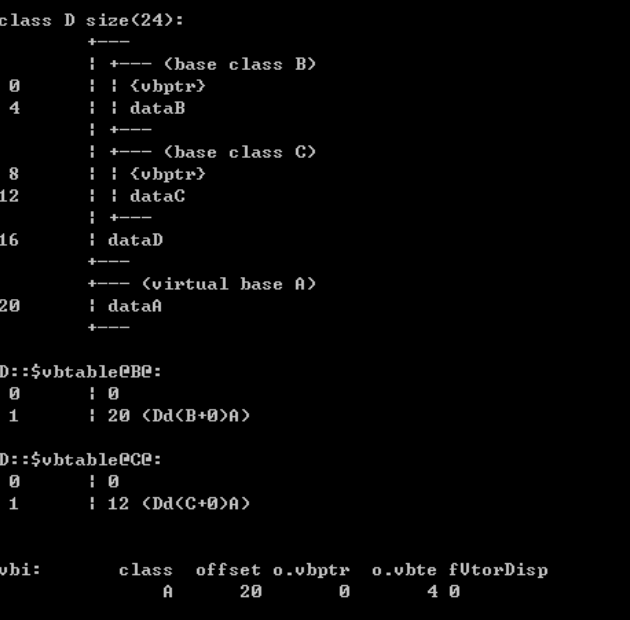 D:vbptr + offset of B to A + offset of C to A
D:vbptr + offset of B to A + offset of C to A我们可以看到,菱形继承体系中的子类在内存布局上和普通多继承体系中的子类类有很大的不一样。对于类B和C,sizeof的值变成了12(因为加了vbptr指针)……
类D 除了继承B、C各自的成员变量dataB、dataA和自己的成员变量外,还有两个分别属于B、C的指针。于是类D对象的内存布局就变成如下的样子:
vbptr:继承自父类B中的指针
int dataB:继承自父类B的成员变量
vbptr:继承自父类C的指针
int dataC:继承自父类C的成员变量
int dataD:D自己的成员变量
int A:继承自父类A的成员变量
虚表中记录了vbptr与本类的偏移地址;第二项是vbptr到共有基类元素之间的偏移量。
在这个例子中,类B中的vbptr指向了虚表D::$vbtable@B@,虚表表明公共基类A的成员变量dataA距离类B开始处的位移为20,这样就找到了成员变量dataA,而虚继承也不用像普通多继承那样维持着公共基类的两份同样的拷贝,节省了存储空间。