
《Python源码剖析》
本文内容主要来源于《Python源码剖析》及相关资料
有机会建议实际手操一遍python源码,模拟虚拟机和内存管理
Python是基于C实现的,主要是用C的结构体(struct)。包括库和模块、解释器和虚拟机几个部分:
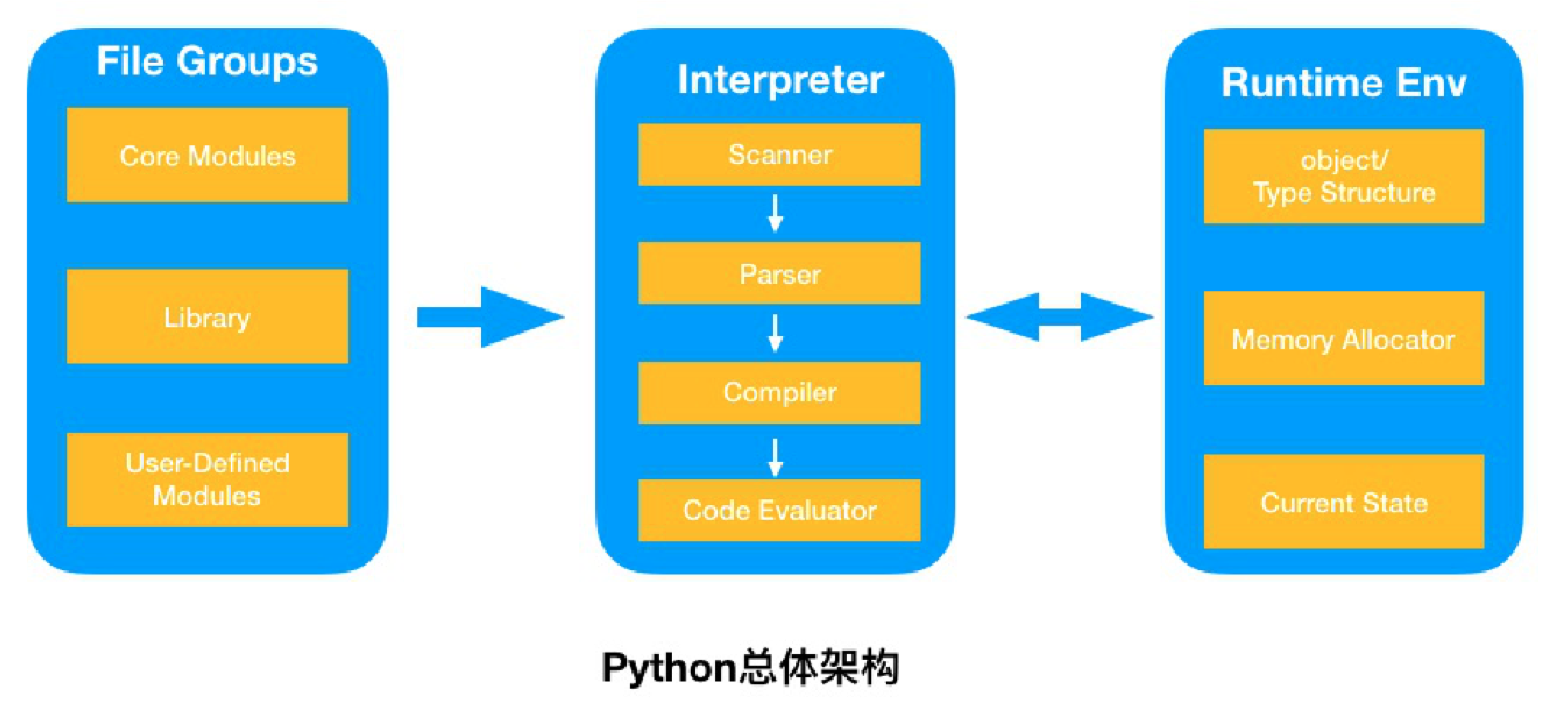
Python2.7源码:
- Include: 头文件部分
- Lib: 自带标准库,用python编写
- Module: 用C编写的模块
- Objects: 所有python内建对象
- Parser: 解释器的scanner和parser部分
- Python: 包含了解释器的compiler和执行引擎部分
对象(C中结构体在堆上申请的一块内存)
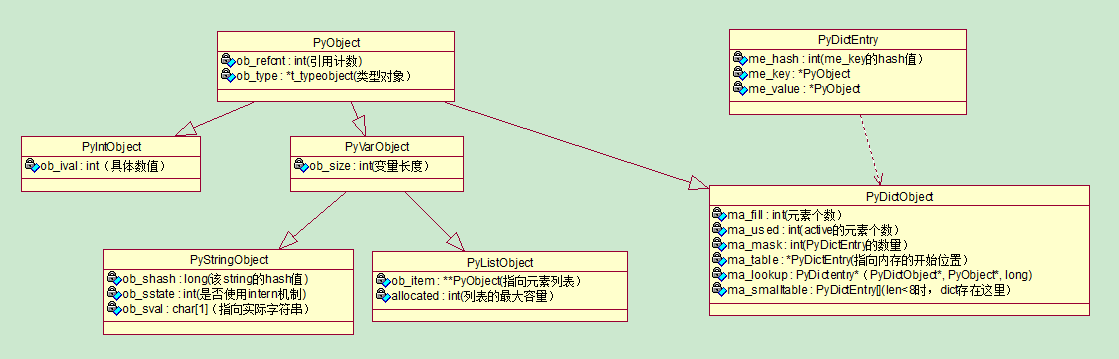
在Python中,万物皆对象:即都基于PyObject,而对象本质就是C结构体,源码可证:
typedef struct _object {PyObject_HEAD} PyObject;
解开PyObject_HEAD,发现它其实是
#define PyObject_HEAD \_PyObject_HEAD_EXTRA \ // DebugPy_ssize_t ob_refcnt; \ // 引用计数(Py_ssize_t相当于unsigned)struct _typeobject *ob_type; // 类型对象
- python对象不能是被静态初始化的, 并且也不能是在栈空间上生存的。除了类型对象(type object)都是被动态初始化的
- 一个对象一旦被创建,它在内存中的大小就是不变的了。这就意味着 需要容纳可变长度数据的对象只能在对象内维护一个指向其他内存区域的指针。这种设计有利于内存管理,避免动态修改内存大小导致的地址变化
在python内部,每个对象都拥有相同的头部(PyObject_HEAD)。因此,PyObject* 可以引用任意一个对象,python内部传递的也是该泛型指针,至于所指对象究竟是什么类型,则由对象的ob_type域判断(由此实现多态)
对象分类
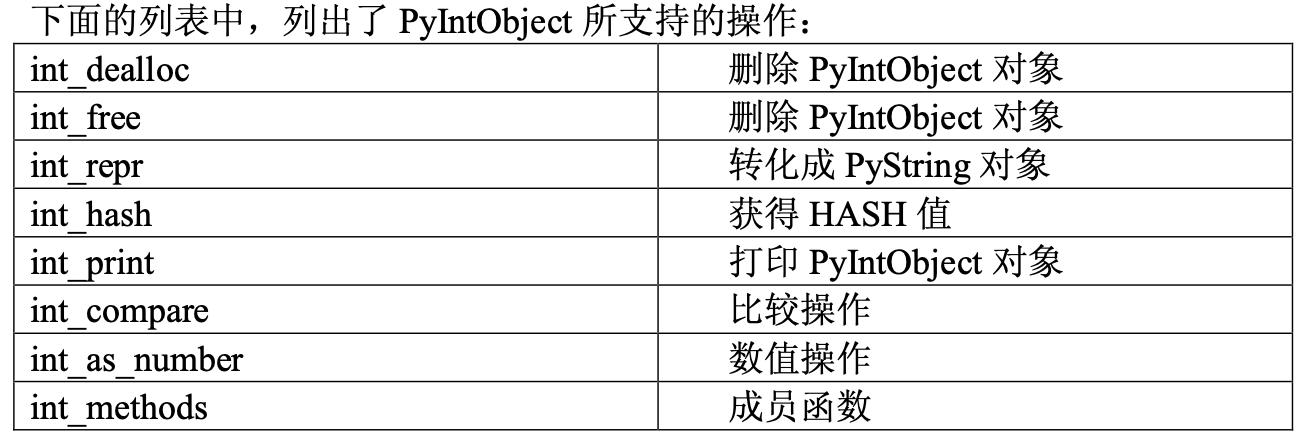
定长对象:如int 基于PyIntObject
[intobject.h]typedef struct {PyObject_HEADlong ob_ival;} PyIntObject;
- 除了HEAD之外,实际只有一个long
- 进行基本的数值操作的时候,都是拿intObj->ob_ival进行操作
- 它的类型对象是PyInt_Type,定义了许多相关的int_methods,如加法溢出时转为PyLongObject:
不定长对象:如string, list 基于PyVarObject
typedef struct {PyObject_VAR_HEAD} PyVarObject;#define PyObject_VAR_HEAD \PyObject_HEAD \Py_ssize_t ob_size;
- 其基于PyObject_VAR_HEAD,是对PyObject的拓展,相比PyObject_HEAD增加了一个ob_size,因此能记录大小的不断改变
引用计数机制
在Python中,主要是通过 Py_INCREF(op)和 Py_DECREF(op) 两个宏来增减一个对象的 ob_refcnt引用计数。
- 当一个对象的引用计数减少到 0 之后,Py_DECREF 将调用该对象的 析构函数(tp_dealloc) 来释放该对象所占有的内存和系统资源。
- 在每一个对象创建的时候,Python提供了一个_Py_NewReference(op)宏来将对象的引用计数初始化为 1。
- 类型对象是超越引用计数规则的,因为类型对象永远不会被析构
- 一般来说,Python中大量采用了内存对象池的技术,使用这种技术避免频繁地申请和释放内存空间。因此在析构时,通常都是将对象占用的空间归还到内存池中。这一点在接下来对 Python 内建对象的实现中可以看得一清二楚
以PyStringObject为例,ob_size记录长度,char[]
[stringobject.h]typedef struct {PyObject_VAR_HEADlong ob_shash; // 缓存该对象的 HASH 值,初始-1int ob_sstate; // 是否使用intern(共享短字符串)机制char ob_sval[1]; // char[]也是以'\0'结尾的,但因为size的存在其中间其实是可以出现'\0'的} PyStringObject;
- 这是一个immutable对象,只能由FromString或FromStringAndSize创建
- python会为 空字符'' 建立一个 PyStringObject 对象,将这个 PyStringObject 对象通过 Intern 机制进行共享,然后将 nullstring 指向这个被共享的对象

hash算法(位运算)

看得出来有个循环,还是没有那么快的
Intern机制在创建字符串之后
Python 并不是在创建 PyStringObject 时就通过 interned 实现了节省空间的目的。事实上,从 PyString_FromString 中可以看到,无论如何,都要先创建一个 PyString_FromString 对象再比较其是否有intern,而且PyString_InternInPlace 也只对 PyStringObject 起作用。
为什么必须要这样?因为intern机制依赖于PyDictObject,而其必须以PyObject作为键,因此无法直接在C字符串上做查找。
创建的String对象分两类,SSTATE_INTERNED_IMMORTAL 状态的 PyStringObject 对象是永远不会被销毁的。
而对PyListObject来说,ob_size=len(list),PyObject* []指向可变内存区域
typedef struct {PyObject_VAR_HEADPyObject **ob_item; // 指向各元素的指针数组Py_ssize_t allocated; // 可容纳元素的总数,相当于capacity,始终>=ob_size} PyListObject;
- 创建: PyList_New,具有free_lists缓冲池技术(存PyListObject*),优先从池中拿出来使用
- 添加: PyList_Append
- 插入: PyList_Insert,会在不够用时进行list_resize、会将插入点后的元素后移、与vector非常相似
- 移除: list_remove ....等等
- 销毁listObj的时候,不一定会立即释放,而是放在free_lists中以备后用,但是list中的各元素引用计数肯定是要改变的
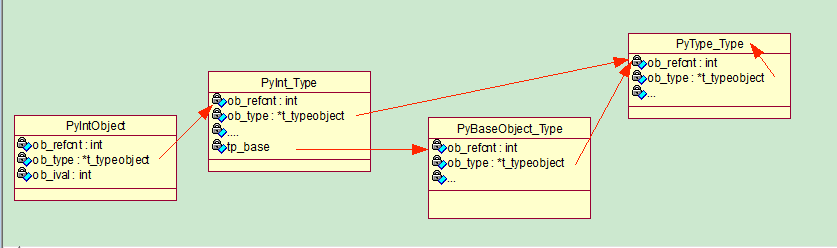
类型对象,主要记录了类型名(tp_name)、空间大小(basicsize, itemsize)、类型操作(hashfunc...)等 类型需要的元信息
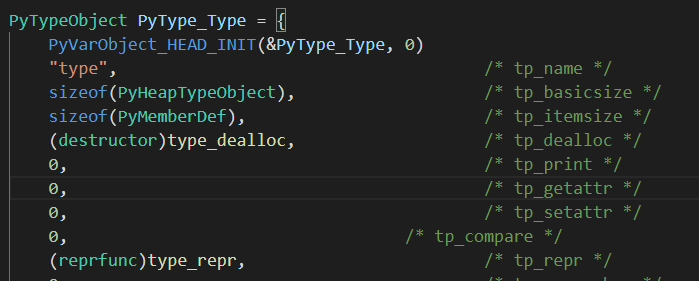
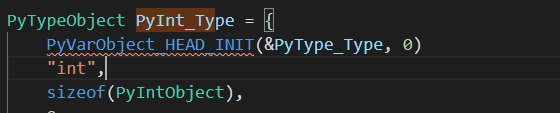
以int为例,定义PyInt_Type为int的类型,基于PyType_Type的PyTypeObject对象:
类型也是一个对象,而类型的类型,是PyType_Type对象
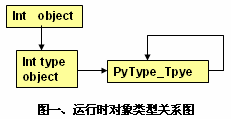 类型的类型是type,type的类型还是type
类型的类型是type,type的类型还是typePyDictObject
entry(成员) 有 Unused/Active/Dummy(伪删除) 三种状态
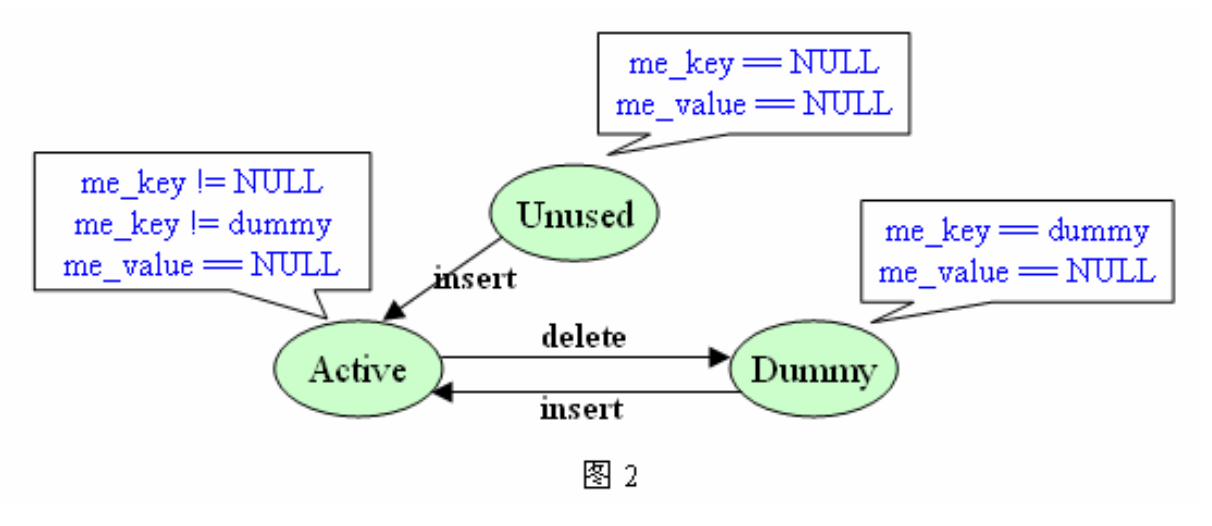
[dictobject.h]#define PyDict_MINSIZE 8 // dict最小成员数typedef struct {Py_hash_t me_hash; // 存储key的hash值PyObject *me_key; // keyPyObject *me_value; // value} PyDictEntry;typedef struct _dictobject {PyObject_HEADint ma_fill; // Active和Dummy的成员个数int ma_used; // Active的成员个数int ma_mask; // 成员总数PyDictEntry *ma_table; // 额外成员空间PyDictEntry *(*ma_lookup)(PyDictObject *mp, PyObject *key, long hash);PyDictEntry ma_smalltable[PyDict_MINSIZE]; // 初始成员空间} PyDictObject;
python中采用的处理hash冲突的方法是 开放定址法,也就是遇到冲突就再搜下一个位置,无论查找还是赋值都是如此(时间换空间)
但是这种方法如果删掉了探测链中间的某个元素,后面的元素即使在表里也会找不到了。因此python不能真正把它删除,只能是做标记
创建
在第一次调用 PyDict_New 时,会创建在一个PyStringObject类型的 dummy 对象,作为一种指示标志。表明该 entry 曾被使用过,且探测序列下一个位置的 entry 有可能是有效的,从而防止探测序列中断。
创建的过程首先申请合适的内存空间,然后在 EMPTY_TO_MINSIZE 中,会将 ma_smalltable 清零,同时设置 ma_size 和 ma_fill,当然,在一个 PyDictObject 对象刚被创建的时候,这两个变量都应该是 0。然后会将 ma_table 指向 ma_smalltable,并设置 ma_mask,可以看到,ma_mask 确实与一个 PyDictObject 对象中 entry 的数量有关。
在创建过程的最后,将 lookdict_string 赋给了 ma_lookup。正是 ma_lookup 指定了 PyDictObject 在 entry 集合中搜索某一特定 entry 时要进行的动作,它是 PyDictObject 的搜索策略,万众瞩目。
搜索
PyDictObject 引入了两个不同的搜索策略,lookdict 和 lookdict_string。实际上,这两个策略使用的是相同的算法,lookdict_string 只是 lookdict 的一种针对 PyStringObject 对象的特化形式。
以 PyStringObject 对象作为 PyDictObject 对象中 entry 的键在 Python 中是如此地广泛和重要,所以 lookdict_string 也就成为了 PyDictObject 创建时所默认采用的搜索策略
lookdict 采取的策略非常简单,直接将 hash 值与 entry 的数量做一个与操作,结果自然落在 entry 的数量之下。由于 ma_mask 会被用来进行大量的与操作,所以这个与 entry 数量相关的变量被命名为 ma_mask,而不是 ma_size。
参考Dict原理(C#)
buckets主要用来进行Hash碰撞(冲突),它的长度是hash表的真实长度
entries 用来存储字典的内容,并且标识下一个元素的位置(实际元素数)
buckets是数组,entries是链表。另外还有用于记录要删除元素的freeList指针
两者的容量都为大于字典容量的一个最小的质数
Add操作:依次 Test.Add(4, 11, 18)
假如我们构造一个 Dictionary test = new Dictionary(6); 那么它的实际map大小是7
我们添加4,4.GetHashCode()%7= 4,因此碰撞到buckets中下标为4的槽上,而元素放在Entries中第0个元素上,此时count变为1
添加11/18的时候,由于再次碰撞到下标为4的slot,这个时候新元素会添加到count+1的位置,因此该slot指向entries[1],entries[1]指向entries[0]
由此可见 所有hashcode相同的元素都形成了一个链表,如果元素碰撞次数越多,链表越长。所花费的时间也相对较多。 而且后加入的会先找到

Remove操作:依次Test.Remove(4, 18) 再.Add(20)
删除元素时,通过一次碰撞,并且沿着链表寻找3次,找到key为4的元素所在的位置,删除当前元素。并且把FreeList的位置指向当前删除元素的位置,当前元素的Next指向上一个FreeList元素,形成了一个链表。FreeCount+1
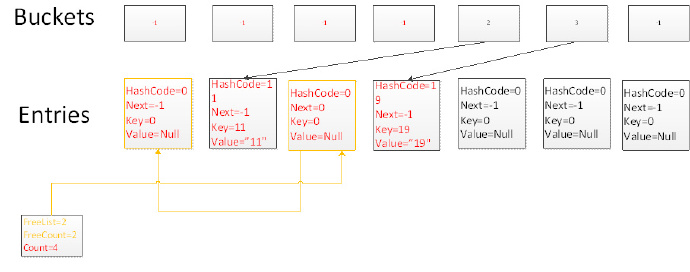 添加一个元素,字典会优先添加到FreeList链表所指向的位置,添加后FreeCount减1
添加一个元素,字典会优先添加到FreeList链表所指向的位置,添加后FreeCount减1通过以上试验,我们可以发现Dictionary在添加,删除元素按照如下方法进行:
- 通过Hash算法来碰撞到指定的Bucket上,碰撞到同一个Bucket槽上所有数据形成一个单链表(与python不同,用的是开链法)
- 需要buckets和entries两个数组来实现间接索引(空间换时间)。默认情况Entries槽中的数据按照添加顺序排列
- 删除的数据会形成一个FreeList的链表,添加数据的时候,优先向FreeList链表中添加数据,FreeList为空则按照count依次排列
- 字典查询及其的效率取决于碰撞的次数,这也解释了为什么Dictionary的查找会很快。
对象池 / Intern机制
dealloc(析构) 和 free(释放) 操作是分开的,析构后不一定回收内存
python的内置变量类型都有自己的对象缓冲池 如int类型的缓冲池范围: -5 ~ 257
对于-5 ~ 257 范围内的数值, 创建后python 会将其加入缓存池当中,当再次使用时,则直接从缓存池中返回
而对其它整数,Python 运行环境将提供一块内存空间,这些内存空间由这些大整数轮流使用
内存管理
python内存结构:block-pool-arena
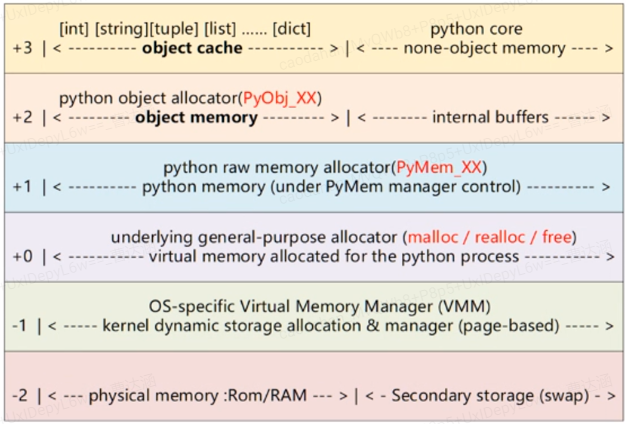
3:对于一些常用对象,构建对象缓冲池机制
2:PyObj_XX(如PyObj_Alloc),提供创建python对象的接口
1:基于系统内存管理接口的包装 PyMem_XX
0:操作系统提供的内存管理接口(malloc/realloc/free)
-1:操作系统级别的内存管理 os分页
-2:物理内存、硬盘等介质 Rom/RAM
PyIntBlock 结构:

[intobject.c]#define BLOCK_SIZE 1000 /* 1K less typical malloc overhead */#define BHEAD_SIZE 8 /* Enough for a 64-bit pointer */#define N_INTOBJECTS ((BLOCK_SIZE - BHEAD_SIZE) / sizeof(PyIntObject))struct _intblock {struct _intblock *next;PyIntObject objects[N_INTOBJECTS];};typedef struct _intblock PyIntBlock;static PyIntBlock *block_list = NULL;static PyIntObject *free_list = NULL;
就是说这个结构里维护了一块(block)内存,其中保存了一些 PyIntObject 对象,size是1000。从 PyIntBlock 的声明中可以看到,在一个 PyIntBlock 中维护着 N_INTOBJECTS 对象,做一个简单的计算,就可以知道是 82 个。显然,这个地方也是 Python 的设计者留给你的可以动态调整地地方,不过,你需要再一次地修改源代码并重新编译。
PyIntBlock 的单向列表通过 block_list 维护,而这些 block 中的 PyIntObject 的列表中可以 被使用的内存通过 free_list 来维护。最开始的时候,这两个指针都被设置为空指针。
也就是存放的PyIntObject每超过82时,就要由PyIntBlock链到的下一个对象来存放了
事实上有一个free_list指向目前有剩余空间的block,如果指向null,就要创建一个新的block
那么问题来了,假如free_list指向block2,而block1中有对象删除了,python怎么知道block1这里有空余的内存呢??
实际上,不同 PyIntBlock 对象之间的 空闲内存块是被链接在一起的,形成了一个单向链表,表头就是 free_list。
由 block_list 维护的 PyIntBlock 的列表中的内存实际是所有的大整数对象所共同分享的。
当一个 PyIntObject 对象被删除时, 它所占有的内存并没有被释放,归还给系统,而是继续被保留着。但是这一块内存现在已经是归 free_list 所维护的链表所有了,这表明在 PyIntObject 对象被删除后,它所占用的内存 成了一块自由内存,可以供别的 PyIntObject 使用了。int_dealloc 完成的就是这么一个简单的 指针维护的工作。当然,这些动作是在删除的对象确实是一个 PyIntObject 对象时发生的。 如果删除的对象是一个整数的派生类的对象,那么 int_dealloc 不做任何动作,只是简单地调用派生类型中制定的释放函数。
看图你就懂了……free_list会指向刚刚dealloc出来的内存,它是一个后进先出的链栈,下一个元素可以链到另一个block里的自由空间,这样就能知道哪些内存是可用的了
小整数对象池的初始化
在 small_ints 中,我们看到,它维护的只是 PyIntObject 的指针,而小整数对象是在什么地方被创建和初始化的呢?完成这一切的神秘的函数正是_PyInt_Init。
内存池机制
在python中很多时候申请的都是小块内存,频繁的申请、释放影响了python的效率。内存池机制用于管理小块内存的申请和释放。
接口:PyObject_Malloc、PyObject_Realloc、PyObject_free
内存池结构:block、pool、arena、内存池(概念上的内存管理机制)
一个block固定为512字节。当申请的内存大小超过512,申请内存的请求会被转交给第一层处理。

不同内存大小范围的会放到不同的block

一组block的集合称为pool
-> 一个pool管理一堆的内存块block
-> pool管理一大块内存,按一定策略分为多个小的内存块
-> 一个pool的大小一般为一个系统内存页(4kb)

pool概念的实现:pool_header 与其他pool链接,组成双向链表
4KB - pool_header = pool维护的block的集合占用的内存
szidx:一个pool管理的block大小是一样的,szidx就是block的size class index

多个pool的聚合就是arena
一个arena大小是256KB,容纳64个pool
- 一个完整的arena包括一个arena_object和透过这个arena_object管理着的pool集合
- pool_header管理的内存与pool_header自身是一块连续的内存,而arena_object与其管理的内存是分离的
- 当pool_header被申请,它所管理的block集合的内存也被申请了,当arena_object被申请,它所管理的pool集合内存没有被申请。
- 多个arena构成的集合,是一个arena数组,数组首地址由arenas维护。
- 当一个arena没有与pool集合建立联系,处于"未使用"状态。一旦建立了联系,就进入"可用"状态。对两种状态都有一个arena链表,分别是unused_arena_objects(通过nextarena链接,单向链表)和usable_arena_objects(通过nextarena和prearena连接,双向链表)
- 申请arena时,会先检查是否还有未使用的arena,有则从单向链表中抽取出arena,并断绝联系。
pool状态
- used状态:pool中至少有一个block被使用,至少还有一个block未被使用。受控于python内部维护的usedpool数组
- full状态:所有block都已经被使用,这种pool在arena中,但不在arena的freepools链表中。
- empty状态:所有block都未被使用,这类pool的集合通过其pool_header中的nextpool构成一个链表。表头就是arena_object中的freepools
分配&释放
- 当申请特定大小小块内存时,首先根据大小寻找对应usedpool,如果没有可用的pool,会从usable_arena中第一个可用的arena获得一个pool。如果usable_arena为空,python会申请一个arena并构建usable_arena链表。
- 当释放一个block,pool可能从used状态变为empty状态,或者从full变为used。若回收了block之后pool仍处于used状态,block被重新放到自由block链表中。若从full回到used,将pool链回到usedpool即可。
- 从used变为empty时,将pool链到freepools中。如果arena中的pool都是empty的,释放pool集合占用的内存。

python中的垃圾收集只关注可能会产生循环引用的对象。
PyIntObject、PyStringObject等对象内部不可能持有其他对象的引用,所以不会产生循环引用
循环引用只发生在container对象之间。(内部可持有其他对象引用的对象,如list、dict、class等)
python追踪这些对象的方法是用双向链表管理这些对象。
一个container对象想成为可收集对象,除了PyObject_HEAD, 还需要PyGc_HEAD:

当python为container对象申请空间,也为PyGc_HEAD申请了空间。
container内存结构:1、PyGc_HEAD 2、PyObject_HEAD 3、自身对象的数据
- python回收其实只是将它在block/pool的那个地方置空,总的申请空间不会变(需要调到底层才会还给系统)
- 内存合并只会合block,因为一个pool是一个页
- 一个pool里的block大小都是一样的,block-pool-arena,先查找有没有相应的pool,然后把对象存进这个pool的block
- 分代回收,步进式回收,优化GC卡顿
Python编译原理
虚拟机类型(stack-based/Register-based VM)
解释型语言往往主用 基于栈的虚拟机,指令精简(相比汇编 opcode),存储在栈中(JVM,C#,Py)
而 基于寄存器的虚拟机 性能更好,但实现也更复杂,Lua有部分使用
.py文件的编译结果是.pyc文件,然后再交给VM虚拟机按序执行,parser和virtual machine都封装在dll中
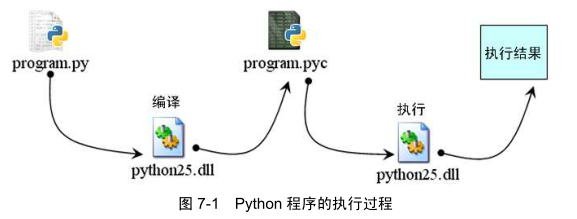
python字节码不是汇编,而是形似的一种自设语言
PyCodeObject
在 Python 源代码中包含的静态的信息都会被 Python 收集起来,编译结果中 包含了 字节码指令序列(PyStringObject),变量名(varnames),栈空间(stacksize) 等等在源代码中 出现的一切有用的静态信息
在程序的运行期间,一段代码(Code Block)会创建一个PyCodeObject对象保存其编译结果,存在于内存中
一般来说,一个作用域就对应着一个block
/* Bytecode object */
typedef struct {
PyObject_HEAD
int co_argcount; /* Code Block位置参数个数 */
int co_nlocals; /* Code Block中局部变量个数,包括其位置参数个数 */
int co_stacksize; /* 执行该段Code Block需要的栈空间 */
int co_flags; /* N/A */
PyObject *co_code; /* 编译得到的字节码指令序列,以PyStringObject的形式存在 */
PyObject *co_consts; /* PyTupleObject,保存Code Block中的所有常量 */ 常量区
PyObject *co_names; /* PyTupleObject, 保存Code Block中的所有符号 */ 可查找
PyObject *co_varnames; /* Code Block中的局部变量名集合 */
PyObject *co_freevars; /* Python实现闭包存储内容 */
PyObject *co_cellvars; /* Code Block中内部嵌套函数所引用的局部变量名集合 */
PyObject *co_filename; /* Code Block对应的.py文件的完整路径 */
PyObject *co_name; /* Code Block的名字,通常是函数名或类名 */
int co_firstlineno; /* Code Block在对应py文件中的起始行 */
PyObject *co_lnotab; /* 字节码指令与py文件中source code行号的对应关系,以PyObjectString形式存在 */
void *co_zombieframe; /* for optimization only (see frameobject.c) */
PyObject *co_weakreflist; /* to support weakrefs to code objects */
} PyCodeObject;
Pyc(二进制文件)
Python 在执行完 PyCodeObject 中的byte code后,会销毁 PyCodeObject(节约内存)
因此需要Pyc文件负责持久化保存pyCodeObject序列化后的信息(节省编译时间)
> 也就是说,在代码不变的情况下,仅第一次需要编译pyc文件,后续直接读取即可 dis.dis()
import abc时,首先会在path搜寻abc.pyc或abc.dll文件,没有就会找abc.py编译成pyc
python还会将字节码偏移值与代码块在源代码的行数记录在co_lnotab,方面tb调试
Code对象
执行compile后会返回code对象,是在python层面对PyCodeObject的简单包装,可以通过其访问源码信息
Pyc文件生成过程
在对一个 PyCodeObject 对象进行写入到 pyc 文件的操作(marshal_write)时,如果碰到它包含 的另一个 PyCodeObject 对象,那么就会递归地执行写入 PyCodeObject 对象的操作。最终所有的PyC对象都会被写入到pyc文件中,所以pyc文件中的PyC对象也是以一种嵌套的关系联系在一起的
字节码
在opcode.h中 #define了许多宏对应的字节码,Python 的执行引擎就是根据这些 byte code 来进行一系列的操作
所有这些字节码的操作含义在 Python 自带的文档中有专门的一页进行描述
这些都可以改的,反外挂常用
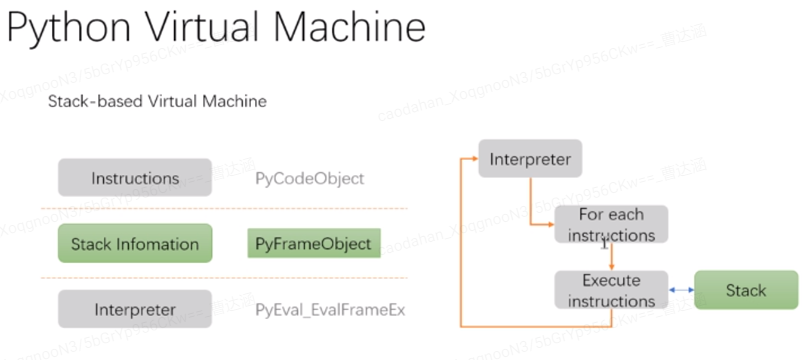
我们有了pyc文件之后,接下来,python虚拟机中模拟了进程(系统资源基本单位)和线程(程序执行最小单位)两个概念,分别是PyInterpreter(State)和PyTreadState(帧栈)
VM通过调度算法在多个线程上切换,最后进入PyEval_EvalFramEx函数,它的作用是foreach instructions : switch opcode,一条一条执行,类似CPU执行指令的过程
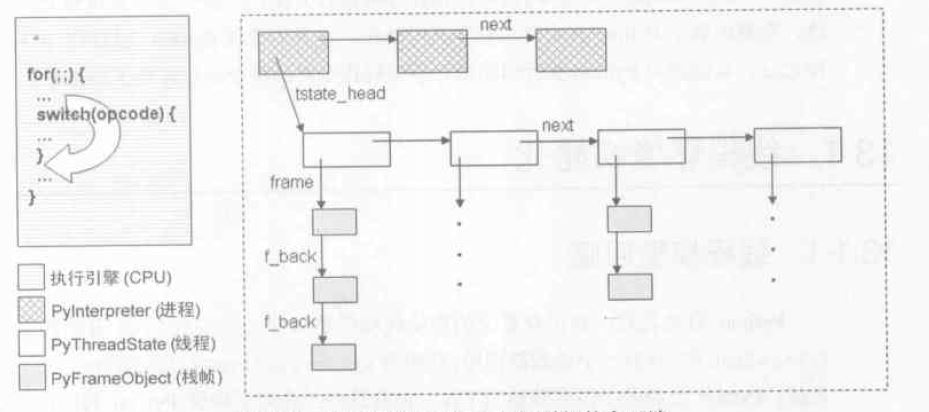
PyEval_EvalFrameEx首先会初始化一些变量。也初始化了堆栈的栈顶指针stack_pointer指向f->f_stacktop。PyCodeObject对象中的co_code域中保存着字节码指令和字节码指令的参数,Python虚拟机执行字节码指令序列的过程就是从头到尾遍历整个co_code、依次执行字节码指令的过程
在Python虚拟机中,利用3个变量来完成整个遍历过程。co_code实际上是一个PyStringObject对象,而其中的字符数组才是真正有意义的东西,整个字节码指令序列实际上在C中就是一个字符数组。因此,遍历过程中所使用的3个变量都是char *类型的变量,first_instr永远指向字节码指令序列的开始位置,next_instr永远指向下一条待执行的字节码指令的位置,f_lasti指向上一条已经执行过的字节码指令的位置
 执行原理
执行原理Python虚拟机的运行框架,实际上就是对CPU的抽象,可以看做一个软CPU,Python中所有线程都使用这个软CPU来完成计算工作。真实机器的任务切换机制对应到Python中,就是使不同的线程轮流使用虚拟机的机制
CPU切换任务时需要保存线程运行环境。对于Python来说,在切换线程之前,同样需要保存关于当前线程的信息。在Python中,这个关于线程状态信息的抽象是通过PyThreadState对象来实现的,一个线程将拥有一个PyThreadState对象。所以从另一种意义来说,这个PyThreadState对象也可以看成是线程本身的抽象。但实际上,这两者是有很大的区别的,PyThreadState并非是对线程本身的模拟,因为Python中的线程仍然使用操作系统的原生线程,PyThreadState仅仅是对线程状态的抽象
在通常情况下,Python只有一个interpreter,这个interpreter中维护了一个或多个的PyThreadState对象,与这些PyThreadState对象对应的线程轮流使用一个字节码执行引擎
PyFrameObject(代码实际的执行环境)
每当发生函数调用时,会创建新的栈帧PyFrameObject,并作为"当前帧" 进入运行时栈,它包含 builtins, globals, locals名字空间 以及 f_back, pyCodeObject, lineno等必要信息
对于一个函数而言,其所有对局部变量的操作都在自己的栈帧中完成,调用了其他函数就要创建新栈帧
typedef struct _frame{
PyObject_VAR_HEAD // "运行时栈"的大小是不确定的
struct _frame *f_back; // 执行环境链上的前一个frame,很多个PyFrameObject连接起来形成执行环境链表
PyCodeObject *f_code; // PyCodeObject 对象,这个frame就是这个PyCodeObject对象的上下文环境
PyObject *f_builtins; // builtin名字空间 dict
PyObject *f_globals; // global名字空间 dict
PyObject *f_locals; // local名字空间 dict
PyObject **f_valuestack; // "运行时栈"的栈底位置
PyObject **f_stacktop; // "运行时栈"的栈顶位置
...
int f_lasti; // 上一条字节码指令在f_code中的偏移位置
int f_lineno; // 当前字节码对应的源代码行
...
// 动态内存,维护(局部变量+cell对象集合+free对象集合+运行时栈)所需要的空间
PyObject *f_localsplus[1];
} PyFrameObject;
- 从f_back我们可以看出一点,在Python实际执行的过程中,会产生很多PyFrameObject对象,而这些对象会被链接起来,形成一条执行环境链表。这正是对x86机器上栈帧间关系的模拟
- 在f_code中存放的是一个待执行的PyCodeObject对象,而接下来的f_builtins、f_globals、f_locals是3个独立的名字空间
- 而在编译一段Code Block时,会计算出这段Code Block执行过程中所需要的栈空间大小。这个栈空间大小存储在PyCodeObject的co_stacksize中。因为不同的Code Block在执行时所需的栈空间大小不同,所以决定PyFrameObject的开头一定有一个PyObject_VAR_HEAD
注意区分 帧栈 和 栈帧,前者是模拟的系统栈、包含后者,后者包含一个运行时栈、也就和我们平时调用函数时用的一样 LOAD_CONST压入的栈
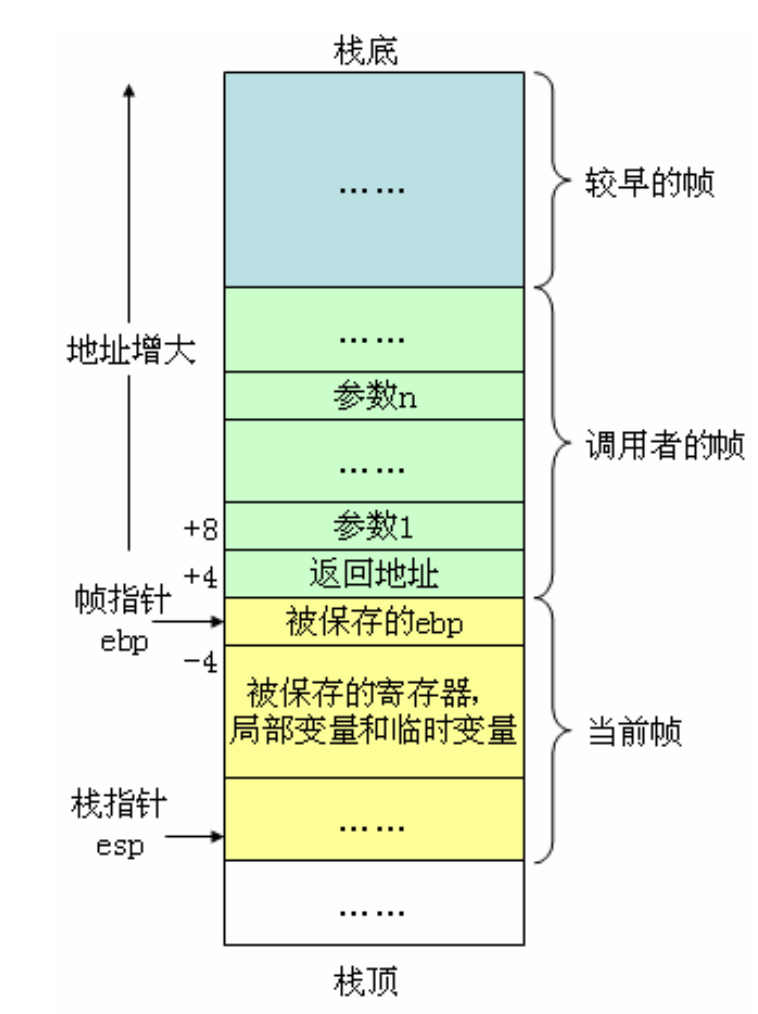 帧栈和它里面的栈帧
帧栈和它里面的栈帧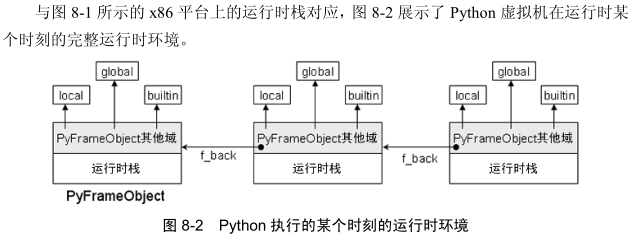 系统栈和运行时栈
系统栈和运行时栈在编译一段Code Block时,会计算出这段Code Block执行过程中所需要的栈空间大小。这个栈空间大小存储在PyCodeObject的co_stacksize中
因为不同的Code Block在执行时所需的栈空间大小不同,所以决定PyFrameObject的开头一定有一个PyObject_VAR_HEAD
创建PyFrameObject对象时,额外申请的那部分内存中有一部分是给PyCodeObject对象中存储的那些局部变量:co_freevars、co_cellvars。而另一部分才是给运行时栈使用的。所以,PyFrameObject对象中栈的起始位置(也就是栈底)是又f_valuestack维护的,而f_stacktop维护额当前的栈顶
在Python中访问Frame对象
frame = sys._getframe()
frame.f_code
caller = frame.f_back
caller.f_locals
PyFunctionObject
在python中,bound/unbound method都是对象,function自然也是对象
python中函数的定义,发生在虚拟机执行def 语句对应的指令序列时。下面是PyFunctionObject的定义:
typedef struct {
PyObject_HEAD /* 解开来就是ob_refcnt:int(引用计数)和ob_type:_typeobject(类型信息),这两个是每个对象的基本构成
PyObject *func_code; /* 对应函数编译后的PyObjectCode对象 */
PyObject *func_globals; /* 函数运行时的global名字空间 */
PyObject *func_defaults; /* 默认参数(NULL 或 a tuple) */
PyObject *func_closure; /* NULL or a tuple of cell objects , 用于实现闭包 */
PyObject *func_doc; /* The __doc__ attribute, can be anything函数的文档(PyStringObject) */
PyObject *func_name; /* The __name__ attribute, a string object 函数名称,函数__name__属性(PyStringObject)*/
PyObject *func_dict; /* The __dict__ attribute, a dict or NULL 函数的__dict__属性 */
PyObject *func_weakreflist; /* List of weak references */
PyObject *func_module; /* The __module__ attribute, can be anything */
} PyFunctionObject;
func_code指向函数编译后的PyCodeObject,func_defaults存放默认参数,对应关系如下:
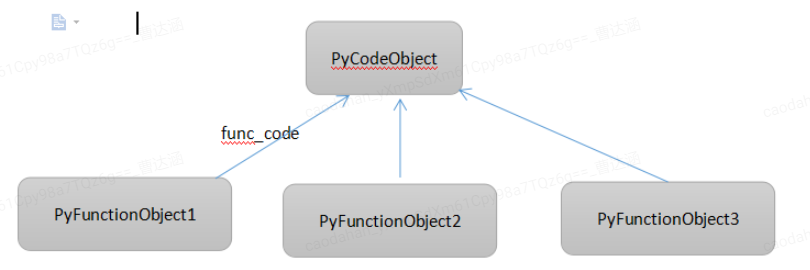
我们可以梳理一下在我们写一个def f()的时候,python实际上做了什么事情:
- 通过LOAD_CONST 0,将函数f对应的PyCodeObject对象压入到运行时栈
- 执行MAKE_FUNCTION,根据这个PyCodeObject创建一个PyFunctionObject对象。
- MAKE_FUNCTION结束后,又再次把PyFunctionObject压入栈中。
- 通过STORE_NAME, 为名字赋一个引用对象,对象由栈顶弹栈得到(即3压入的对象)。
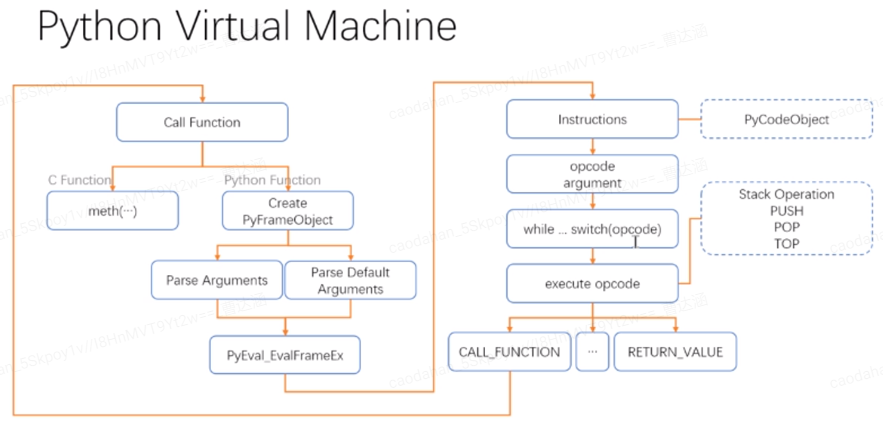
函数调用
上面执行f()的过程中,最重要的是CALL_FUNCTION,里面的代码比较多,这里就不一一详述,我们来看下最后调用的函数fast_function:
static PyObject *
fast_function(PyObject *func, PyObject ***pp_stack, int n, int na, int nk)
{
PyCodeObject *co = (PyCodeObject *)PyFunction_GET_CODE(func);
PyObject *globals = PyFunction_GET_GLOBALS(func);
PyObject *argdefs = PyFunction_GET_DEFAULTS(func);
PyObject **d = NULL;
int nd = 0;
if (argdefs == NULL && co->co_argcount == n && nk==0 &&
co->co_flags == (CO_OPTIMIZED | CO_NEWLOCALS | CO_NOFREE)) {
PyFrameObject *f;
PyObject *retval = NULL;
PyThreadState *tstate = PyThreadState_GET();
PyObject **fastlocals, **stack;
int i;
......
f = PyFrame_New(tstate, co, globals, NULL);
......
retval = PyEval_EvalFrameEx(f,0);
......
}
.......
}
 无参/有参 调用区别
无参/有参 调用区别1.Python虚拟机通过PyFrame_New(state, co, globals, NULL)创建新的PyFrameObject对象,其中co为函数f的PyCodeObject对象,globals为函数对象PyFunctionObject的global名字空间。
2. 调用PyEval_EvalFrameEx把PyFrameObject放入栈帧中执行,这个过程大概是:创建新的栈帧,并且在栈帧中执行代码。
我们留心一下的话,会惊奇的发现PyFrame_New里面的参数只有PyCodeObject和global名字空间,PyFunctionObject已经消失的无踪无影了。也就是说,PyFunctionObject主要是对字节码指令和global进行打包和传输,最终的执行栈帧中,并没有PyFunctionObject。
……
 Fast Call
Fast Call总结!执行流程
遇到Python函数 - 参数转换 - EvalFrame - 获取pyc指令 - opcode解析 - 执行对应opcode - 递归调用or返回