
7. C++ 编译原理
Windows下 c++程序的生成过程(MSVC):
- 编写-源程序 .cpp
- 预编译-预处理文件 .i
- 编译-汇编文件 .asm
- 汇编-目标程序 .obj
- 链接-可执行程序 .exe
源程序:是指用源语言写的,有待翻译的程序。
预编译:处理#预编译指令,处理宏展开,合并头文件到源文件中...等(IDE就是从.i文件中得到预编译信息提示的)
编译:把源程序转化为目标程序的过程,通常由编译器(compiler)完成。中间经过汇编转换(可选),最终得到一个COFF统一格式的二进制机器码文件
目标程序:源程序通过编译加工以后生成的机器语言程序,为二进制目标文件(object File)。
链接:将一个或多个目标文件以及依赖的库文件链接为可执行文件的过程,通常由链接器(linker)完成。
> 链接与编译相对独立。链接器只关注COFF格式的目标文件,只要目标文件的格式统一,那么链接器就可以链接由不同编译器编译出来的目标文件
lib文件:静态链接库文件。对于使用该库的源程序,编译器会在编译阶段将用到的库函数代码 直接链接进目标程序,这样程序运行的时候不再需要其它的库文件,代价是生成的程序体积会更大。
> 在Linux下为.a文件,由于静态库文件的代码已经在obj文件中展开,所以生成的可执行文件不需要引用额外的文件
dll文件:动态链接库文件。对于使用该库的源程序,编译器会在编译阶段将用到的库函数所在文件和位置信息 链接进目标程序,这样程序运行的时候需要从该库文件中加载并寻找相应函数代码,代价是需要相应dll文件的支持。
> 在Linux下为.so文件,由于动态库文件的代码只存在于自身文件中,所以生成的可执行文件必须要引用相应的dll文件才可运行
编译器:cl.exe
链接器:link.exe
编译器路径:Path
VC++包含目录:Include
VC++库目录:Lib
编译过程:词法分析,语法分析,语义分析,源代码级优化,目标代码生成及优化
> 识别各种符号->生成语法树->解析表达式语义->转换成中间代码->生成目标机器的机器代码
编译优化选项:在编译时,可以通过-O指令选择优化方案,对源代码进行编译器层面的调优
词法分析
使用 扫描器(Lexer),原理是:确定有限自动机(DFA)
识别 Token(单词),分为标识符(包括 变量名、符号、保留字)、数值、字符串等,可能有不同的书写规则,不能有歧义
比如我们要处理的是正则语言,那么用正则表达式就可以匹配正则语言
语法分析
识别输入符号串是否为一个句子,通常会建立语法树
自上而下分析
LL(1) 预测分析法 ...
自下而上分析
算符优先分析
LR ...
语义分析
静态语义:编译时就可以确定的语义(如类型声明、标识符、常量表达式)
动态语义:运行时才可以确定的语义(如数值计算、下标越界、无效指针)
四元式(三地址指令) 三元式


查符号表,将指令翻译为机器语言
符号表
存储 标识符 到 属性 的映射

除上述,属性还可能包括层数(level 嵌套定义) 、偏移量(offset 局部变量分配空间首地址偏移量)等
我们参考一下python是怎么编译和解释的
.py -> Parser(Lexical Analysis→Syntactic Analysis→AST)->.pyc 词法分析和语法分析转字节码
字节码中的代码,其实已经变成了Abstract Syntax Trees,生成过程是:
ParserReadFile→Tokenizer→(Read&Parse Token→Add TreeNode)→Return TreeRoot→Compiler Assemble to Bytecode
.pyc -> Read Instructions→opcode+arguments→switch(opcode) ->exec
COFF文件中的段种类
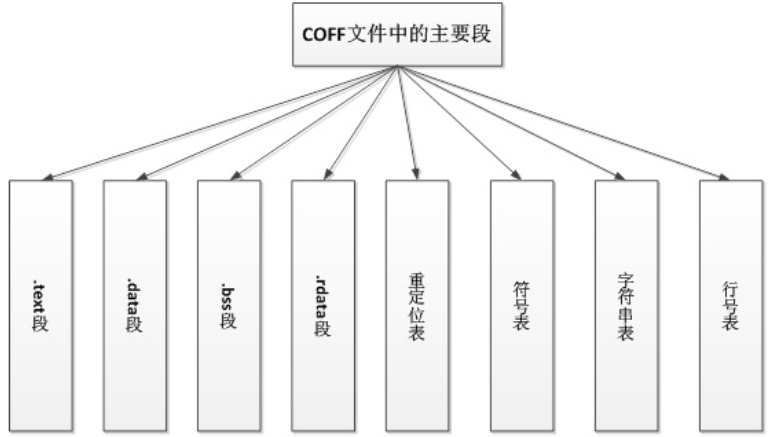 符号表、字符串表等
符号表、字符串表等链接过程
在C++程序的编译阶段,编译器是以".CPP"文件为单位进行编译的。也就是说,对于每一个".CPP"文件,都会生成一个".obj"目标文件。在目标文件中,对于每一条指令或者指令要操作的数据,都应该生成一个虚拟内存的地址。如果一个目标文件中要使用的函数或者数据被定义在另外一个目标文件中,如:在A.obj文件中调用了B.obj文件中定义的函数。在将A.CPP生成A.obj的过程中,是无法马上确定该被调用函数的地址的。因为该函数的地址记录在B.obj文件中。
在形成可执行文件的过程中,链接器需要将在编译阶段无法确定的被调用符号(函数,变量)的虚拟内存地址确定下来。这就是链接的主要目标。
> 所以为什么有时候我们编译过了、链接没过,大有可能是调用的外部符号出了问题
注:关于每个指令的虚拟内存地址,在目标文件中,该地址以相对于文件某个位置的偏移来表示;直到PE文件生成的时候,才会将这些偏移值转换成虚拟内存地址。
链接库可能会有依赖关系,需按顺序引入别的链接库……
多个编译单元的符号地址可能是相同的,比如都从 (0x0000) 开始,那么最终多个目标文件链接时就会导致地址重复。所以链接器在链接时就会对每个目标文件的地址进行调整,这个调整的过程就是重定位。
在执行了链接以后,将多个目标文件合并在一起,输出了 exe可执行文件 或者是 dll动态链接库。
可执行文件和动态链接库的二进制内容是以PE格式存储
PE文件中的段种类
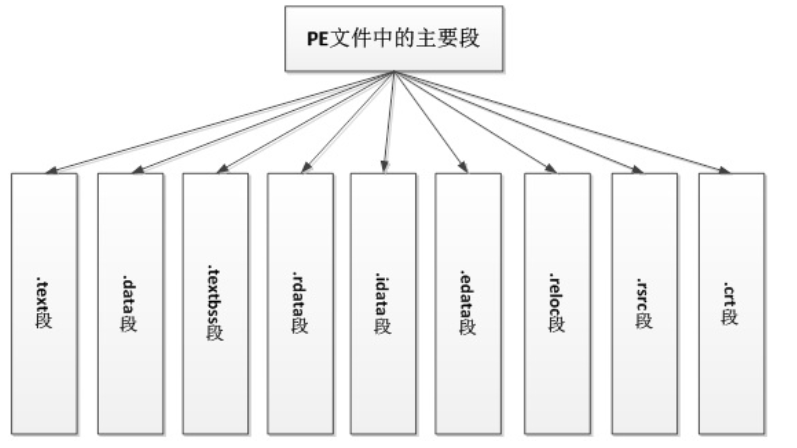
进阶……
unix下的c++编译、链接、工具流程(gcc, gdb, cmake)
使用工具分析编译链接流程的各种中间文件
1. shared library和dynamic linking基础
2. 虚拟内存
3. gcc编译,gdb调试等工具的基础用法
4. shared library和PIC基本原理
5. 使用工具分析动态链接过程
6. 从编译和链接角度介绍程序设计和优化技巧