
5. C++ STL
标准库以header files的形式呈现
写C++ STL的注意点:
- stl容器 应尽量用 const vector
- stl的容器,从来都不是免费多线程用的
- spinlock很快, atomic很快, 请使用spinlock, atomic
- boost的stl同名的类, 在跨平台上比stl稳
- vector加速:插入大量元素前,先reserve一次, 就可以避免大量的reallocate和复制
- vector尽量不要用at (里面有检查range, 会慢很多); 用operator[]
- emplace_back大部分情况比push-back好(这个就是C++11的move语义大展神威的系列了, 所有容器都应该尽量用emplace; 具体看c++11的move)
STL六大组件
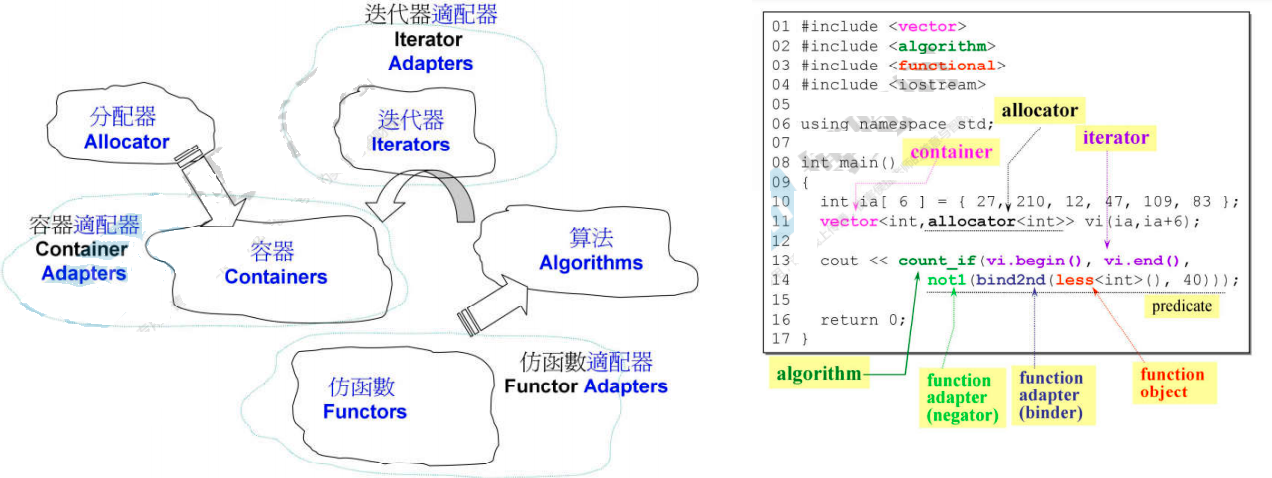
容器
STL中的容器大体分为序列容器、关联容器和无序容器.
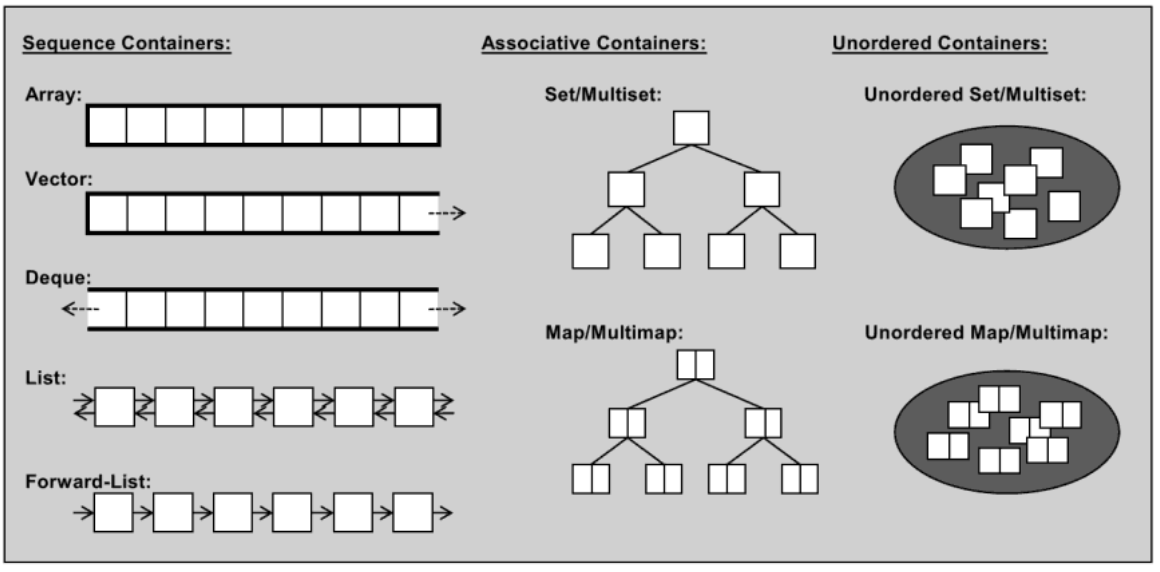
array
等同于数组,抽象成了模板类,不赘述
vector
动态数组,空间建立连续。一开始默认大小为0,放入一个元素后容量变为1……
vector对使用者是连续的,因此重载了[]运算符.
vector的实现也是连续的,因此使用指针类型做迭代器 (即迭代器vector::iterator 的实际类型是原生指针T*)
扩容:根据具体的STL实现与编译器实现,通常当容器满(又要插入新数据)时开始扩容,申请一块新的内存并进行内存的拷贝,一般为1.5~2倍大小
任何操作,一旦引起vector空间重新配置,指向原vector的所有迭代器就都失效了
扩容时会调用对象的构造函数吗?
STL中考虑到异常的情况,因此,像这种容器内部的复制行为,是要求不能够发生异常的,因此,只有当移动构造函数声明为noexcept的时候才会调用,否则将统一调用拷贝构造函数。
删除:erase 删除元素会使其后面的元素前移,pop_back 就不会。删除元素 并不会改变数组的capacity,但是会改变它的size,因此访问超出size的下标会越界
缩容:vector 的容量是不会自动缩减的,需要你主动修改capacity(reverse / shrink_to_fit 或 swap(v2))。如果只是改大小也可以用resize
priority_queue默认基于vector实现
list
双向链表,内存空间不连续,通过指针进行数据访问
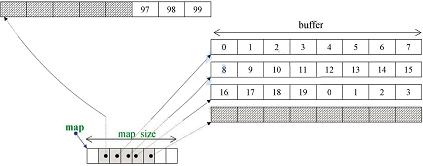
deque
双头队列,随即存取,完全可代替vector
stack和queue默认基于此实现
set 与 unordered_set 与 multiset和unordered_multiset
红黑树 / 哈希表 / 重复key支持
因为 multimap 支持重复的key,因此不能使用重载的 [] 运算符进行插入
map 与 unordered_map 与 multimap....
一般是哈希表占内存更大,因为Dict不仅需要存Entry,还需要Buckets索引到Entries,但是比map更快
unordered_map的底层实现是hashtable,采用开链法(也就是用桶)来解决哈希冲突【和python类似,用多个链表,而不像C#用entries单链表】
unordered_map插入过程是:
- 计算hash(key)=hashcode值
- 计算index=hashcode%buckets.size()拿到桶号
- 桶中的每个元素其实都是链表指针,用链表结点存放key, value
默认桶的大小为10,出于泊松分布规律(随机hash分布下桶长度大概率小于8),扩容因子为0.8。即当桶装满8个的时候 扩容,rehash到扩容约一倍(而且也是二进制幂,计算更快)
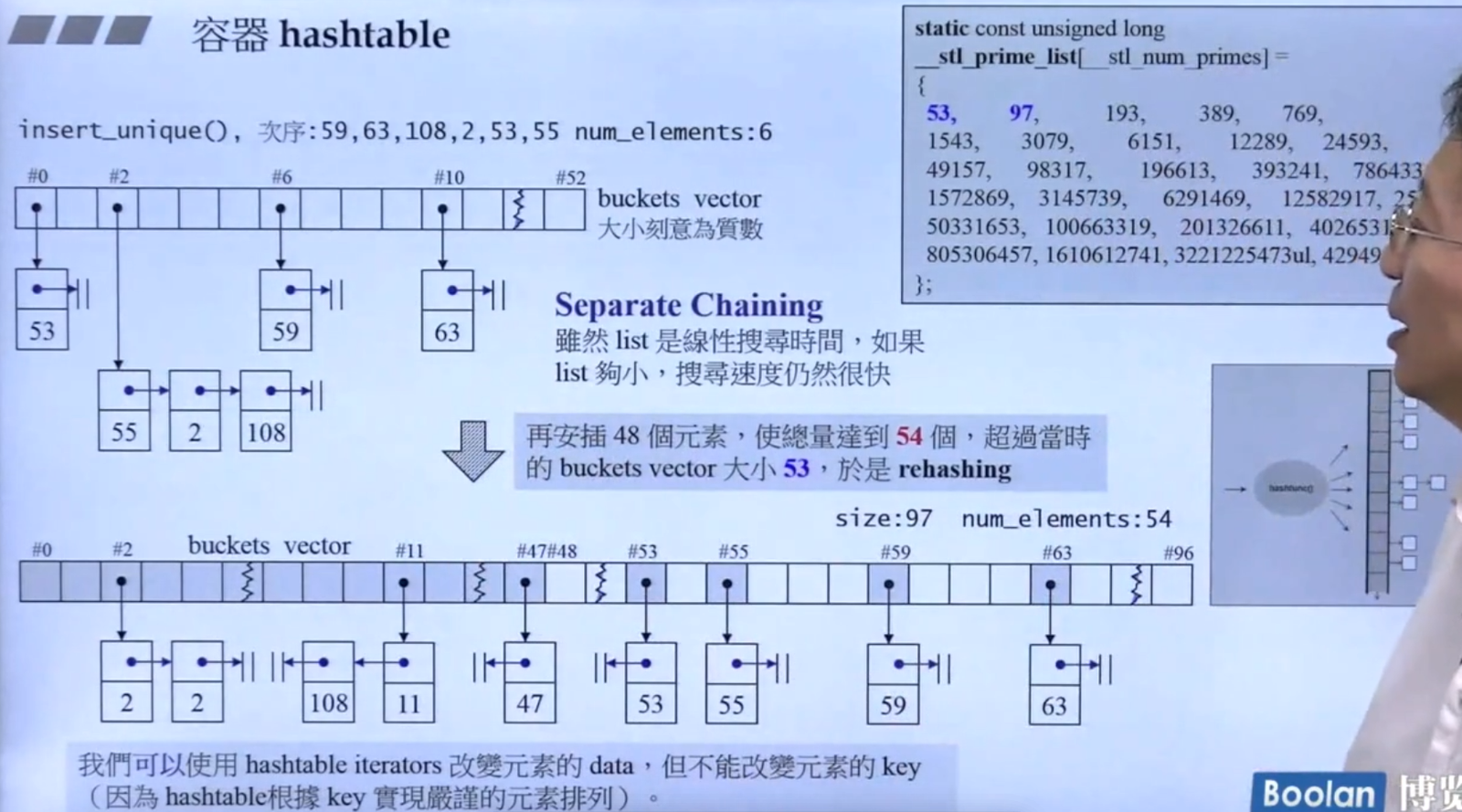
如演示中桶初始大小53,用于进行%除留余数法计算hashcode应放的位置。当元素个数超过53时,对buckets vector进行扩容,到接近一倍的某个素数(有预存素数表),然后再把原先存放过的hashcode重新计算一遍、分配位置(打散元素),这样能提高桶的利用率,减少因桶太小、碰撞次数变多带来的效率损耗
python,C#的dict
python是有一个默认8个元素的小dict(可设置size),超过这个数再创建一个大dict来存。
C++是bucket里面装链表指针(开链法),而python是一个Entry链表装所有Entry(元素),采用开放定址法,每次冲突就得再搜索下一个,但是也因此要删除的元素不能真删,而是要标记、以防断了探测链
C#是有buckets和entries两个数组的区分,前者只用来处理碰撞,后者只用来存放元素(单链表)
C#字典中只有两个链表,即Entries数据链表 和 FreeList删除链表
dict查找效率基本取决于碰撞的次数,所以减少碰撞次数很有必要
sort
泛型算法