
1. C++ Primer 侯捷讲
C++推荐书籍
- C++ Primer
- Effective C++系列
- 深度探索C++对象模型
- STL源码剖析
- C++ Templates
视频教程:Geekband 侯捷C++系列
实践方式
- DirectX 引擎开发
- Unreal C++编写
- Leetcode 算法编程
- Project 个人项目(如DependencyGraph)
- 开源项目 / 写作业
C++是个语言联邦,它有多条路线:
- 面向对象编程(OOP)
- 模板与泛型编程(TGP)
- 并发编程
- C与STL
- 函数式、元编程等
我主用的Unreal,也是其中一条路线,是以UC++形式编程的一种用法
C++的演化
- B语言
- C语言 -> new C → C with Class → C++
- C++98/03
- C++11/14
- C++17/20
C++标准库(Standard Template Library)
Object Based:面对的是单一class的设计
Object Oriented:面对的是多重classes的设计,class和class之间的关系
基础方面不赘述,请直接看 C++ 菜鸟教程,侯捷老师的C++ Primer是直接从类讲起的
数据类型,变量,注释,常量,作用域,运算符,if,while,for,指针,数组,字符串,容器,函数,引用,类&对象...
或者读《A Tour of C++》,对应《C++ Primer》1~8章
C++代码组织形式
.h .cpp .hpp
头文件中,常采取防卫式宏声明:#pragma once,效果等同于
#ifndef __CLASSNAME_H__#define __CLASSNAME_H__...#endif
> 编译器处理包含文件的方式是将其展开在源文件当中,所以如果不加这个条件编译指令,头文件的内容会在同一个源文件里面多次展开,那么编译器就会报错,说同一个东西被多次定义
.hpp比较方便,声明+定义一起写会更省事,但规范的项目中还是要分开。.h与.hpp都有作为头文件的功能,但前者可与C兼容,后者只用于C++
值传递vs引用传递
C++中,完全是由自己决定用哪种传递的,更考验程序员设计功力
但是,通常更推荐传引用
如果我在函数内新建了一个对象,然后return该对象的引用
- 如果是栈上创建的,那么它会作为local变量被回收,引用也就会变空。所以在栈上创建的对象不应该返回引用,而是直接返回该对象
- 如果是堆上则不会。因此,如果想要返回某对象的引用,该对象应该在堆上创建
入口函数(Entry-Point Symbol)
Windows默认为 C Runtime:void mainCRTStartup()
这个函数定义在Visual C++安装目录的crt\src\目录下的某个.c文件中(视VC++的版本不同,存放的文件也不同)。它在执行一些初始化操作,如获取命令行参数、获取环境变量值、初始化全局变量、初始化io 的所需各项准备之后,调用main(argc,argv)。main函数返回后,mainCRTStartup还需要调用全局变量的析构函数或者atexit()所登记的一些函数
在可执行文件执行时,操作系统创建进程与主线程后,就从mainCRTStartup开始执行主线程
简单说,编译器把全局变量的初始化代码的入口地址当作一个无参数无返回值类型的函数指针(即 void (*fp)()的原型),都依次存放在可执行文件的.CRT节中,构成了一个函数指针表。mainCRTStartup通过调用_initterm函数(定义在cinitexe.c文件)遍历这个函数指针数组,依次调用每个函数指针,完成全局变量的初始化工作。
入口函数可自己定义,要求调用main函数
main函数
int _tmain(int argc,_TCHAR* argv[]) {...} // 为支持unicode[tchar.h]中#define _tmain main
定义在类内部的成员函数,或用inline标识符修饰的函数,称为内联函数
可以提高效率(就地展开,无需跳转),但只能是短代码段(建议10行内),否则编译器并不会把它作为inline实现
现在的编译器已然能自动的标记内联,在大多数情况下比人类做得更好。写inline是一个好习惯,但也不必特意使用
构造函数有比较多的细则,从中可以窥探编译器的设计思路
通常我们写一个无参构造函数就是:
ctor() = default; // 要求编译器生成默认构造函数,并赋给我们定义的构造函数
默认构造函数(无参构造函数)的好处是他会使用默认值去初始化成员变量(如果成员是类的话就会调用那个类的默认构造函数)
构造函数是内存分配成功后的回调函数,因此它不存在返回值
更多时候我们会需要传参初始化:
A(int i,string n):id(i),name(n) {...} // 初始值列表
更推荐使用初始值列表(Initilization List)初始化字段的原因是:
初始值列表相当于定义并初始化该字段 id=i;
而函数体内再赋值则是先定义再赋值的 int id; id=i;
甚至,初始值列表调用的是拷贝构造函数 name(n)
这比赋值运算符要更快代码行数通常更少 name=n;
注意,初始化列表会先于构造函数执行(可以理解,毕竟字段先初始化才好执行逻辑)
且成员的初始化顺序与它们在类定义中出现的顺序一致
Why?因为编译器不能确定初始化顺序会不会有依赖关系,而且析构的时候也是要先析构后构造的。假如我是编译器,我也只能按类定义顺序构造
还有委托构造函数:
A(): A(1, "") {...} // 先调用其他构造函数来完成该构造的初始化
子类的构造函数往往会委托父类的构造函数来构造
我们把只有一个参数、且该参数又不是本类的const引用,这种构造函数称为 转换构造函数。作用是将一个其他类型的对象转换成该类的对象
A(string n): A(1, n) {...} // 如我们定义了一个string转换构造函数void Func(const A&) {...} // 定义了一个函数要求传入A类型string name="kira"; // 这时定义一个string类型Func(name); // name传入Func是合法的!string被隐式转换为了A类型Func("kira"); // 但是,你不能直接传入字符串,因为const char[]到string也会经过一步类型转换,而编译器只允许一步类类型转换(不合法)
可以用explicit来抑制构造函数定义的隐式转换
- 关键字explicit只对一个实参的构造函数有效
- 在类外部定义成员函数时不需要使用explicit关键字
支持将该类型转为其他类型的函数
A::operator string() { return name; }A a("kira");string name = a; // 通过类型转换函数,触发隐式类型转换
- 同样可用于隐式类型转换(没有主动写转型代码)
- 写法类似于运算符重载函数,让编译器可以将该对象作为string型数据处理
转换构造函数和类型转换运算符有一个共同的功能: 当需要的时候,编译系统会自动调用这些函数,建立一个无名的临时对象(或临时变量)。
要注意滥用该特性可能导致 多义性 编译报错,因此合适时机用explicit可以避免 产生歧义 ambiguous
聚合类
有时我们会定义一个数据集合(用class或struct),它没有任何类的特点(无基类无虚函),也没有定义给它初始化的方式(无构造无初始值),那么编译器会把它识别为聚合类,让你可以用 {成员初始值列表} 来初始化它:
struct Data{int id;string name;};Data d = {1000, "Anotts"}; // aggregate initialization
声明哪些变量时必须初始化:
- 对于const或者&类型的变量,必须初始化。
- 对于没有定义默认构造函数的类,其对象必须初始化
拷贝构造函数
以const T&的形式编写
A(const A& a): A(a.id, a.name) {...} // 同样推荐用初始化列表哦
如果你没写,编译器会提供默认的,但默认拷贝构造函数只是浅拷贝(单纯复制每个数据成员的值),如果有指向堆内存的变量,就有可能出现野指针的问题了!(引用的对象被销毁了)
重载赋值运算符
有返回值,其他与拷贝构造函数相似
A& operator=(const A& a) {...} // 重载=运算符要考虑的情况往往更多,如原本已有值的情况该怎么处理(拷贝构造就不用管这点),自赋值等
如果没有 显式地提供一个以本类或本类的引用为参数的赋值运算符重载函数,编译器会自动生成赋值运算符重载函数
运算符重载是多态性的一种表现(有部分不支持多态的运算符不能重载,如sizeof)
运算符重载不可改变其结合性、操作数个数和优先级
析构函数
~A() {...}
系统同样会生成默认的,但是不会释放掉可能指向堆中的内存(只要类中有new就有必要自己写析构)
重载函数(overloading)
Func编译后的实际函数名可能是 ?Func@Classname@@QBENXZ
重载operator+,有多种情况:
- 用于正号(只有一个参数)A operator+(const A& a) { return a;}
- 用于加法(处理两个参数)A operator+(const A& a, int d) { return A(a.id+d, a.name);}
重载operator++,有两种情况:
- 带int参数,为后置递增(要保留初值并返回)
- 不带参数,为前置递增
private修饰的构造函数
通常来说,构造函数应该被public修饰,供外界调用。如果是private,也就是不能由外部创建对象:
- 用于单例模式
- 用于静态类
private修饰的析构函数
- 用于禁止用户对此类型的变量进行定义。要创建对象,只能用 new 在堆上进行!
- 用于禁止用户在程序中使用 delete 删除此类型对象。对象的删除只能在类内实现!
原理:私有成员只能在类域内被访问,不能在类域外进行访问,因此无法在栈上析构
常成员函数
如果一个函数是只读的(不修改数据),那你就应该把它声明为常成员函数
int getId() const { return id;} // 通常getData函数是只读的// 常量对象只能调用常成员函数const A a; a.getId();
一个例外是它可以修改mutable变量,另外如果变量是指针,它其实相当于底层const
mutable int varId; // mutable变量永远可变,甚至当它是const对象的成员时也是如此
如果我们不修改函数参数,也应该尽量将参数设置为const,包括const指针、常引用
常返回值函数
const int& getId() { return id;} // 其实只有在返回引用时才有用,表示该返回值不可修改const int& getId() const; // 可以重载,似乎用于匹配不同情形的用法
> 养成良好的习惯
友元函数:本质是定义在类外的函数(全局域or另一个类域),让类外可以访问该类对象私有成员,友元函数不是成员函数
优点:实现类之间数据共享,减少系统开销,提高效率
缺点:友元函数破环了封装机制
友元类:在类A中指定类B为其单向友元,类A便可访问类B的所有成员(侵入式?)
注:相同类型对象会互为friends(可以访问其私有成员)
class A{friend void Func(A& a); // 声明Func为友元函数,类外定义friend void B::Func(); // 声明类B的Func为本类的友元函数friend class B; // 声明类B为本类友元int friends(const A& a) // 可以访问a的私有成员{ return a.id + int(a.name); }}
友元函数没有this指针,故要访问实例成员一定需要有对象作参数
> 熟悉constructor、destructor、copy constructor和overload operator=
class String{public:String(const char *cstr = ""); // new char[strlen(cstr)+1]String(const String &other); // strcpy(data, other.data)~String(); // delete[] dataString& operator=(const String &other); // if (this == &other) {return *this; delete[] data.. new}String operator+(const String &other) const; // strcat(newString.data,other.data)char* get_c_str() { return data;}private:char *data; // 本质};
现在各大编译器实现的string都有短字符串优化,实现方式是在内部同时持有一个定长char数组和一个char*指针。在字符串数据短时,使用数组存储,这样就可以利用栈内存效率比堆内存高的优势了
一般有如下做法:static成员+if判空实例化,加锁且前后检测是否已经初始化,C#静态构造函数,C++局部静态成员
class Singleton
{
private:
Singleton() { };
~Singleton() { };
Singleton(const Singleton&);
Singleton& operator=(const Singleton&);
public:
static Singleton& getInstance()
{
static Singleton instance; // 利用局部静态变量只会初始化一次的特性(如果把这条写在函数外,就是早启动)
return instance;
}
};
来自Effective C++,Meyers' Singleton,线程安全且晚启动。有C++11规定,在一个线程开始local static对象的初始化后到完成初始化前,其他线程执行到这个local static对象的初始化语句就会等待,直到该local static 对象初始化完成,因此不会造成重复构造和内存泄露
其他知识
引用只是别名,没有内存空间
> 但是实质上,编译器对引用的实现,其实是一个包了一层的地址,指向目标变量的地址(这就像C#、python里引用类型的变量,其实它是封装后的一个指向对象的指针)
数组名的本质是地址常量
i++会产生临时变量,再改变运算对象的值,返回的是原始值的副本(如果编译器有优化,则会和++i差不多)
- 机器字长 指运算器进行定点数运算所能处理的二进制数据位数
- float和int一起运算会转换为double
- 定义全局变量系统会自动初始化,而局部变量会为随机值(栈内存)
隐式类型转换:自动进行。常发生在 实参到形参的类型转换、表达式操作符运算时的类型转换等..
explicit关键字 可以阻止不应该允许的经过转换构造函数进行的隐式转换的发生
显式类型转换通用格式:xxxx_cast (expression)
static_cast(a) 编译时类型检查
static_cast强制转换只会在编译时检查,但没有运行时类型检查来保证转换的安全性。同时,static_cast也不能去掉expression的const、volitale、或者__unaligned属性。
其主要应用场景有:
(1) 用于类层次结构中基类和子类之间指针或引用的转换。进行上行转换(把子类的指针或引用转换成基类表示)是安全的;进行下行转换(把基类指针或引用转换成子类指针或引用)时,由于没有动态类型检查,所以是不安全的。
(2) 用于基本数据类型之间的转换,如把int转换成char,把int转换成enum。这种转换的安全性也要开发人员来保证。
(3) 把void指针转换成目标类型的指针 (不安全!)
(4) 把任何类型的表达式转换成void类型
(5) 将enum class值转化为整数或者浮点数
(6) 转换为右值引用
dynamic_cast(c) 运行时类型检查,用于处理多态 继承体系对象的转换,转换失败 返回nullptr or 抛出引用异常
(1) new_type 必须是一个指针或引用或"指向 void 的指针"。 如果 new_type 是指针,则 expression 的类型必须是指针,如果 type-id 是引用,则expression为左值。 如果转型失败会返回null(转型对象为指针时)或抛出异常(转型对象为引用时)。dynamic_cast 会动用运行时信息(RTTI)来进行类型安全检查,因此dynamic_cast 存在一定的效率损失。
(2) dynamic_cast 的一个重要作用就是要确保转换结果应该指向一个完整的目标类型。一般来说,下行转换用dynamic_cast,其他转换包括上行转换用static_cast。这样你可以判断出下转型是否是成功的
(3) dynamic_cast是根据多态性来判断类型的,所以只能在有多态性质的类之间使用。如果你只是单纯的实现class C : A, dynamic_cast(c)是会报错C is not polymorphic的(你给的类都没有虚函数我咋知道能不能转)
(4) 应用:在指向同一个对象的不同基类指针之间的转换,使用dynamic_cast能够保证转换的正确性。还有就是基类类型的指针,可以指向不同子类对象。但是两个子类类型的指针,是不能指向对方的对象的。如果转换,是会出错的。这时候可以使用dynamic_cast在运行时判断基类指针指向的是哪一个子类的对象。
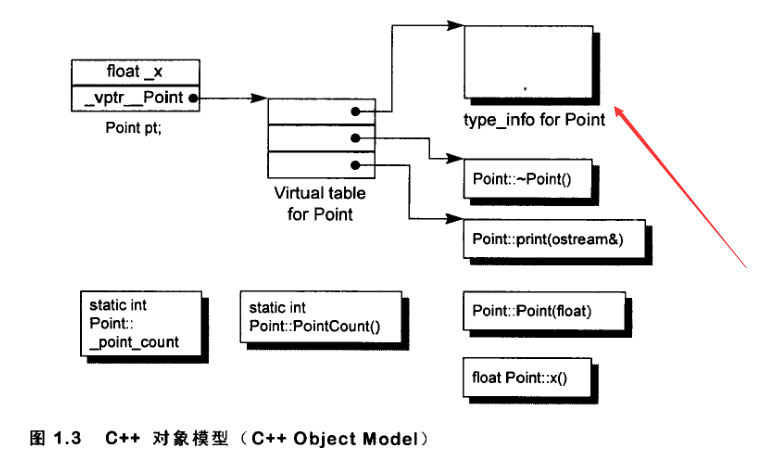
vtable的第一个数据是type_info
根据C++对象模型,对象的type_info被存在了虚表的首部,所以要使用dynamic_cast,对象必须有多态。然后运行时期比对要转换的类型是否和type_info中记录的类型相同即可。
要实现dynamic_cast,编译器会在每个含有虚函数的类的虚函数表的前四个字节存放一个指向_RTTICompleteObjectLocator结构的指针,当然还要额外空间存放_RTTICompleteObjectLocator及其相关结构的数据。即:
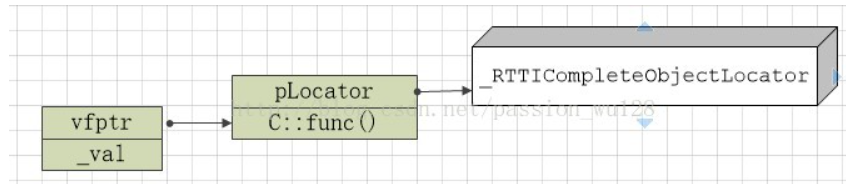
这个_RTTICompleteObjectLocator就是实现dynamic_cast的关键结构。里面存放了vfptr相对this指针的偏移、构造函数偏移(针对虚继承)、type_info指针,以及类层次结构中其它类的相关信息。如果是多重继承,这些信息更加复杂。
所以,dynamic_cast的时间和空间代价是相对较高的,在设计时应避免使用。
如果整个工程都不需要dynamic_cast,可以禁用运行时类型信息,这样编译器就不会产生_RTTICompleteObjectLocator及相关数据。
const_cast(constDoubleVal) 用于去除对象的const或者volatile属性
new_type 必须是一个指针、引用或者指向对象类型成员的指针。
reinterpret_cast 对指针/引用进行原始转换,不做任何偏移处理
new_type 必须是一个指针、引用、算术类型、函数指针或者成员指针。其转换结果与编译平台息息相关,不具有可移植性,因此在一般的代码中不常见到它。
reinterpret_cast 常用的一个用途是转换函数指针类型,即可以将一种类型的函数指针转换为另一种类型的函数指针,但这种转换可能会导致不正确的结果。总之,reinterpret_cast只用于底层代码,一般我们都用不到它,如果你的代码中使用到这种转型,务必明白自己在干什么
type(object) 类型强转,本质上是按照const_cast、static_cast、reinterpert_cast等顺序进行尝试转换
数组相关
数组名是地址常量:a = &a[0]
int a[] = {0,1,2,3}; // 列表自动初始化大小int(* p)[4] = &a; // 数组指针,必须指向4元素大小的数组a+1 = a + sizeof(int) // 数组迭代器&a+1 = a + sizeof(int[4]) // 获取数组尾后元素的地址len = sizeof(a)/sizeof(int); // 计算len的一种方式int*(& rA)[3] = int* pA[3]; // 这是一个指向指针数组的引用
&a的类型是数组指针,int(*)[4]
通常更推荐用vector,其会先开辟较小空间,当需要扩容时会将数据复制到新vector、再释放掉之前的内存
迭代器(容器指针)
- vector
::iterator it 容器迭代器 - const_iterator 常量迭代器,只可读不可写
- (*it).front / it->second 都可以访问对象的成员,这里分别是map的key和value
- inserter 插入迭代器
- iter+1 表示迭代到下一元素,可以由此实现at
- 迭代器循环中增删元素容易造成段错误:访问的内存超出了系统给程序的内存空间
const 迭代器:iter是一个常量,是不能改变的,不能修改指向位置,但是可以修改其值,类似于顶层const
如果你希望指针本身是常量,可以声明 const iterator; 如果你希望指针指向的对象是常量,请使用const_iterator(底层const)
erase,insert,扩容 都会导致失效,因为它们都会导致移位
函数指针
函数传参分值传递和引用传递,而指针传递实质是值传递,即用了另一个指针形参指向了实参的地址,因而如果要改变指针指向或申请内存,则要使用多重指针
- 函数的类型(方法签名):返回类型+形参类型
- 函数指针声明:bool (*pf)( const string&, const string& );
- pf指向函数:pf = (&)lengthCompare;
- pf调用函数:(*pf)( "Hello", "goodbye" ); 解引用 不是必须的
- 函数指针的形参写法,bool (*pf)( const string&, const string& ),这里(*)可以省略
- 函数指针为返回值类型的函数:int (*fun(int))(int *, int); 这里fun(int)是函数,外面是函数指针类型,我们把fun(int)当成pf看就懂了:相当于pf fun(int)
sizeof 运算符永远不会产生 0,即使空类也要分配1的空间,如果不是空类则会要求内存补齐
允许key重复的话请用 multimap/multiset